
从零到一:构建基于大语言模型的多格式文档理解系统 — 技术难点与解决方案全记录
项目名称:表易智融(原"智联文档" / FilesReadSystem)
项目背景:第十七届中国大学生服务外包创新创业大赛 A23 赛题——《基于大语言模型的文档理解与多源数据融合》
开发周期:2026年2月 ~ 2026年5月(约3个月)
技术栈:FastAPI + React + TypeScript + MongoDB + MySQL + Redis + Celery + FAISS + 多LLM集成
一、项目概述
"表易智融"是一个基于大语言模型(LLM)的智能文档处理系统,核心能力包括:
多格式文档解析:支持 Excel (.xlsx/.xls)、Word (.docx)、Markdown (.md)、纯文本 (.txt) 四种格式
AI 驱动的智能分析:文档摘要、关键信息提取、图表数据生成
自然语言指令交互:用户用自然语言描述需求,系统自动完成文档编辑、格式转换、模板填写
模板智能填充:从非结构化源文档中自动提取数据,填入 Word/Excel 模板表格
RAG 检索增强:基于向量检索的语义搜索,辅助 LLM 精准定位信息
本文将从实际的 Git 提交记录出发,全面复盘项目开发过程中遇到的技术难点、踩过的坑、以及最终解决方案。
二、基础设施与架构挑战
2.1 多数据库协同的复杂性
问题描述:系统需要同时使用三种数据库:MySQL(结构化 Excel 数据)、MongoDB(非结构化文档)、Redis(缓存/任务队列)。三者的连接管理、初始化顺序、健康检查逻辑各不相同。
遇到的坑:
MySQL 数据库自动创建失败:当数据库不存在时,
SQLAlchemy.create_engine必须在连接字符串中指定数据库名,但又无法在连接时动态创建MongoDB 连接超时无合理错误提示
Redis 连接健康检查返回假阳性(连接池存在但实际不可用)
解决方案:
# 1. MySQL: 先创建无数据库的临时连接,执行 CREATE DATABASE,再建立正式连接
# 2. MongoDB: 使用 motor 异步驱动,所有操作统一为 async/await 模式
# 3. Redis: 健康检查从简单连接验证改为实际执行 PING 命令
# 4. 所有数据库的健康检查改为执行实际操作(SELECT 1, ping(), PING)而非仅检查连接对象
相关提交:4bdc3f9, 7c88da9, 5fca4eb, 8e1ddb8
2.2 Docker 全栈部署的环境配置
问题描述:项目最终需要支持 Docker 一键部署,涉及 5 个服务(前端 Nginx、后端 FastAPI、MongoDB、MySQL、Redis)的编排,以及开发环境与生产环境的配置差异。
解决方案:
# docker-compose.yml 核心结构
services:
frontend: # React + Nginx 反向代理
backend: # FastAPI + Celery Worker
mongodb: # 非结构化数据
mysql: # 结构化数据
redis: # 缓存 + 消息队列
关键措施:
通过
.env.example统一管理环境变量服务启动依赖链管理(
depends_on+healthcheck)文件路径区分开发/生产环境(本地路径 vs Docker 挂载路径)
Celery Worker 作为独立容器运行
相关提交:d2e3c2d
三、文档解析的深水区
3.1 Excel 解析:pandas 不是万能的
这是项目中遇到问题最多、迭代次数最多的模块。
问题 1:特殊格式 Excel 文件 pandas 无法解析
现象:某些 Excel 文件(包含非标准 XML 元素、自定义命名空间等)用 pandas.read_excel() 打开时报错或返回空数据。
解决:实现 XML 回退解析机制 (XML Fallback Parser)
# xlsx_parser.py 核心逻辑
try:
# 方法1: 标准 pandas 解析
xls_file = pd.ExcelFile(file_path)
sheet_names = xls_file.sheet_names
except Exception:
# 方法2: 直接从 ZIP 内 XML 提取
sheet_names = self._extract_sheet_names_from_xml(file_path)
data = self._read_excel_sheet_xml(file_path)
具体实现:
_extract_sheet_names_from_xml(): 解析xl/workbook.xml提取工作表名_read_excel_sheet_xml(): 直接解析xl/worksheets/sheetN.xml提取单元格数据支持多种命名空间(
http://schemas.openxmlformats.org/spreadsheetml/2006/main等),使用通配符匹配
相关提交:3b82103, 7c19e49
问题 2:XML 命名空间兼容性
现象:不同来源的 Excel 文件使用不同的 XML 命名空间声明方式,导致元素查找失败。
解决:多命名空间同时匹配 + 通配符 fallback
# 尝试多种命名空间前缀
for ns_prefix in ['', 's:', 'ss:', 'x:', 'main:']:
tag = f'{{{ns}}}{element_name}'
result = root.findall(f'.//{tag}')
相关提交:3b82103
问题 3:英文表头 Excel 读取失败
现象:包含英文列名的 Excel 文件,在某些命名空间配置下无法正确识别表头。
解决:增强 Excel 解析器,支持多种命名空间和路径格式的组合查找。
相关提交:496b965
问题 4:浮点数匹配不一致
现象:从 Excel 读取的数字,与使用时的浮点数进行匹配时出现精度不一致问题(如 3.0 != 3.0000000000001)。
解决:在数据类型检测逻辑中优化浮点数范围验证,超出合理精度范围的数值标记为 TEXT 类型处理。
# 改进的类型检测
def _infer_column_type(values):
# 移除空值后才进行类型推断
# 整数:检查是否在 INT 范围内
# 浮点:检查精度在合理范围
# 超出范围 → TEXT
相关提交:718f864, 1a54d40
问题 5:MySQL 列名编码问题
现象:Excel 列名包含中文字符,直接用作 MySQL 列名时报编码错误或创建失败。
解决:实现列名清理逻辑,支持 UTF-8 编码的中文字符,同时处理唯一列名生成(防止重名列),并切换到 pymysql 直接插入方式提升性能。
相关提交:ec47595
问题 6:MySQL “id” 保留字冲突
现象:使用 id 作为列名时,SQLAlchemy 生成的 SQL 语法错误。
解决:识别并转义 MySQL 保留字列名。
相关提交:41e5eaa
3.2 Word 文档解析
问题 1:python-docx 的兼容性局限
现象:python-docx 处理某些复杂格式的 .docx 文件时,表格提取异常或遗漏。
解决:采用 zipfile + 直接 XML 读取 的方式兜底:
# docx_parser.py - 绕过 python-docx 直接读取 XML
import zipfile
from xml.etree import ElementTree as ET
with zipfile.ZipFile(file_path) as z:
with z.open('word/document.xml') as f:
tree = ET.parse(f)
# 直接解析 Word 的 XML 结构
相关提交:be30283
问题 2:Word 模板导出文件损坏
现象:使用 python-docx 修改模板后保存,导出的 .docx 文件无法正常打开。
解决:改用临时文件方式处理输出,确保文件完整写入后再返回。
相关提交:ecad9cc
3.3 Markdown 和文本解析
编码检测挑战:TXT 文件编码不定(GBK、UTF-8、UTF-8-BOM 等),直接读取中文乱码。
解决:引入 chardet 库进行自动编码检测,支持从 GBK/GB2312/UTF-8 等多种编码中自动选择。
相关提交:5bcad4a
四、LLM 集成:最艰难的攻坚战
4.1 LLM 服务商切换的阵痛
项目经历了多次 LLM 服务商变更:
MiniMax → 智谱AI (GLM-4) → DeepSeek
每次切换都面临:
API 格式差异(请求体结构、响应字段名不同)
Token 限制差异(不同模型的最大 token 数差异巨大)
输出风格差异(JSON 格式稳定性、中文理解能力)
流式输出协议差异
最终方案:抽象 LLM 服务层,统一不同供应商的调用接口。
# llm_service.py 核心设计
class LLMService:
def __init__(self):
self.api_key = settings.LLM_API_KEY
self.base_url = settings.LLM_BASE_URL
self.model_name = settings.LLM_MODEL_NAME
# 通过 .env 配置即可切换,无需修改代码
async def chat(self, messages, temperature=0.3, max_tokens=4000):
# 统一的调用接口
async def chat_stream(self, messages):
# 统一的流式调用接口
相关提交:6ec45b7, 5241f68
4.2 max_tokens 的血泪教训
这是项目中反复调整次数最多的参数,经历了经典的"矫枉过正"循环:
初始值: 500 → "不够用,LLM 返回被截断"
修改为: 50000 → "DeepSeek API 报错,超过限制"
修改为: 4000 → "正常运行"
修改为: 5000 → "又报错"
改回: 4000 → "最终稳定值"
教训:
不同 LLM 的 max_tokens 上限不同,需要逐一测试
DeepSeek 的上限远低于预期,约 4000-8000 tokens
参数过大不仅会报错,还可能导致响应变慢和费用增加
最佳实践:针对具体 API 文档逐模型测试边界值,而非猜一个"够大"的值
相关提交:df35105, 2c2ab56, 496b965, 78417c898
4.3 LLM 输出 JSON 解析:与"不听话"的 AI 斗争
这是项目的核心痛点之一。LLM 返回的 JSON 经常处于不可解析状态:
问题表现
// 情况1: Markdown 代码块包裹
```json
{"field": "value"}
// 情况2: JSON 被截断(token 限制导致)
{“field”: “value”, “another”: "val
// 情况3: 末尾多余逗号
{“field”: “value”,}
// 情况4: 非 JSON 噪音混入
根据文档内容,提取结果如下:
{“field”: “value”}
以上为提取结果。
#### 解决方案:多层 JSON 修复策略
```python
# template_fill_service.py 中的 _fix_json 方法
def _fix_json(self, text: str) -> str:
"""多层防御性 JSON 修复"""
# Step 1: 清理 Markdown 代码块标记
text = re.sub(r'```json\s*', '', text)
text = re.sub(r'```\s*', '', text)
# Step 2: 提取 JSON 对象(找第一个 { 到最后一个 })
start = text.find('{')
end = text.rfind('}')
if start != -1 and end != -1:
text = text[start:end+1]
# Step 3: 移除末尾多余逗号
text = re.sub(r',\s*}', '}', text)
text = re.sub(r',\s*]', ']', text)
# Step 4: 尝试配对括号(处理截断)
open_count = text.count('{') - text.count('}')
if open_count > 0:
text += '}' * open_count
return text
终极保险:正则兜底提取
当 JSON 完全无法修复时,使用 正则表达式直接从文本提取值:
def _extract_values_by_regex(self, text: str, field_name: str) -> List[str]:
"""从损坏的文本中用正则兜底提取"""
# 匹配 "field_name": "value" 模式
patterns = [
rf'"{field_name}"\s*:\s*"([^"]*)"',
rf'"{field_name}"\s*:\s*(\d+\.?\d*)',
]
for pattern in patterns:
matches = re.findall(pattern, text, re.IGNORECASE)
if matches:
return list(matches)
return []
相关提交:df35105, 2c2ab56, d5df5b8, a9dc0d8
4.4 Prompt 工程的持续优化
核心挑战:Prompt 既要引导 LLM 生成正确格式,又要保持提取准确率。
经过多轮迭代总结的经验:
相关提交:a9dc0d8, ecc0c79, 7f67fa89
五、RAG 向量检索:从理想到现实
5.1 嵌入模型的安装困境
问题:sentence-transformers 依赖的底层库(torch、onnxruntime 等)在 Windows 上安装困难,且模型下载需要特定网络环境。
解决方案:
添加 try-catch 优雅降级,嵌入模型加载失败时使用简化模式而非崩溃
提供
EMBEDDING_MODEL配置项,支持灵活切换默认使用轻量模型
all-MiniLM-L6-v2
try:
from sentence_transformers import SentenceTransformer
self.embedding_model = SentenceTransformer(settings.EMBEDDING_MODEL)
except Exception as e:
logger.warning(f"嵌入模型加载失败,使用简化模式: {e}")
self._disabled = True # 优雅降级
5.2 RAG 服务的临时禁用决策
背景:在比赛准备阶段,嵌入模型在多个环境下加载不稳定,影响了核心的模板填写功能。
决策:临时禁用 RAG 功能,改用直接文件读取 + LLM 理解 的方式完成数据提取。关键考虑:
RAG 禁用 vs 保留的权衡:
- RAG 优势:语义检索精度高,支持跨文档对比
- RAG 劣势:模型加载不稳定,增加系统复杂度
- 直接读取优势:简单可靠,不需要额外依赖
- 直接读取劣势:无法做语义级检索
结论:比赛场景下,文档数量有限→直接读取更可靠
相关提交:44d389a
5.3 混合检索的实现
当 RAG 服务正常运行时,系统支持 BM25 + 向量检索混合融合:
class RAGService:
def hybrid_search(self, query: str, top_k: int = 5):
"""混合检索:BM25 关键词 + FAISS 向量"""
# 1. BM25 关键词检索
bm25_results = self.bm25.search(query, top_k=top_k*2)
# 2. FAISS 向量检索
vector_results = self.faiss_search(query, top_k=top_k*2)
# 3. 融合排序(RRF - Reciprocal Rank Fusion)
fused = self._rrf_fusion(bm25_results, vector_results)
return fused[:top_k]
相关提交:ecad9cc
六、智能填表:核心业务的演进
6.1 从"一条路"到"双轨制"
初始方案:所有字段都通过 LLM 从文档文本中提取。
问题:对于 Excel 等已有结构化数据(rows/columns)的文档,LLM 提取既不准确又慢。
最终方案:结构化优先 + LLM 兜底
字段提取流程:
1. 检查 source_docs 是否有 structured_data.rows
2. 有 → 直接从 rows 中按列名匹配提取(模糊匹配 + 包含关系)
3. 无 → 使用 LLM 从文本中提取
4. LLM 提取失败 → 正则表达式兜底
async def _extract_field_value(self, field_name, source_docs):
# 优先:结构化数据直接提取
for doc in source_docs:
if doc.structured_data.get("rows"):
values = self._extract_from_rows(
doc.structured_data["rows"],
doc.structured_data["columns"],
field_name
)
if values:
return values, "结构化数据直接提取", 1.0
# 其次:LLM 文本理解
result = await self.llm.extract_field_from_text(field_name, text)
# 兜底:正则表达式
if not result:
result = self._extract_by_regex(field_name, text)
相关提交:2c2ab56, df35105, 7f67fa89
6.2 多值字段的处理
需求:一个模板字段可能对应多个数据值(如"提取文档中的医院数量"→多个医院的统计结果)。
解决:
@dataclass
class FillResult:
field: str
values: List[Any] = [] # 支持多值数组
value: Any = "" # 向后兼容(第一个值)
warning: str = None # 多值检测提示
前端展示时,多值情况显示黄色警告提示,清晰列出所有提取到的值。
相关提交:a9dc0d8
6.3 智能意图解析
实现了支持以下意图的自然语言解析器:
关键创新:支持对话历史感知,基于 MongoDB 中存储的对话上下文延续用户意图。AI 助手能够记住之前的对话内容,实现多轮交互下的意图延续和理解。
相关提交:e5d4724, ecad9cc
6.4 格式转换与 PDF 生成
实现了四种格式互转:docx ↔ xlsx ↔ md ↔ txt ↔ pdf
特别是 PDF 转换的流水线设计:
任意格式 → Markdown(中间格式)→ PDF
这样保证输出一致性,避免了每种格式都要单独写 PDF 渲染逻辑。
中文支持:使用 simhei.ttf 字体文件解决中文 PDF 乱码问题。DOCX 解析使用 zipfile 直接读取 XML,避免 python-docx 的兼容性问题。
相关提交:be30283
七、前端架构的演化
7.1 状态管理重构
问题:TemplateFill 页面状态分散在多个组件和 hooks 中,导致数据流难以追踪和调试。
解决:创建 TemplateFillContext,将模板填写相关的所有状态集中管理。
重构前:
TemplateFill.tsx (300+ 行状态管理)
├── FileUploader (独立状态)
├── FieldEditor (独立状态)
└── ResultPreview (独立状态)
重构后:
TemplateFillContext (全局状态)
TemplateFill.tsx (轻量化,仅 UI 编排)
├── FileUploader (消费 Context)
├── FieldEditor (消费 Context)
└── ResultPreview (消费 Context)
相关提交:7f67fa89
7.2 FastAPI + JSON 请求体的经典问题
现象:后端接口定义使用普通函数参数,FastAPI 将其解析为查询参数而非请求体,导致 JSON 数据无法接收。
# ❌ 错误写法 - FastAPI 当作 Query 参数处理
@router.post("/statistics")
async def generate_statistics(excel_data: Dict[str, Any]):
...
# ✅ 正确写法 - 使用 Pydantic 模型
class StatisticsRequest(BaseModel):
excel_data: Dict[str, Any]
@router.post("/statistics")
async def generate_statistics(request: StatisticsRequest):
...
相关提交:开发日志 2026-03-16
7.3 导入路径漂移
问题:重构时将 AuthContext 从 src/context/ 移动到 src/contexts/,导致多处导入路径失效。
解决:系统性更新所有引用路径(App.tsx, RouteGuard.tsx 等),并删除旧文件避免混淆。
相关提交:5fca4eb
7.4 并行文件上传
需求:用户需要一次上传多个文件,并能看到每个文件的上传状态。
解决:实现并行多文件上传功能,前端显示上传文件列表,支持多次追加上传。配合后端批量接口,提升了用户操作效率。
相关提交:8f66c23
八、异步任务系统的设计
8.1 任务状态双写机制
问题:Celery 的任务状态存储在 Redis 中,但 Redis 有内存淘汰策略,长时间任务状态可能丢失。
解决:实现 Redis + MongoDB 双写
async def update_task_status(task_id: str, status: str, **kwargs):
"""任务状态双写"""
# 1. 写入 Redis(快速查询,支持过期)
await redis.set(f"task:{task_id}", json.dumps({
"status": status, **kwargs
}), ex=3600)
# 2. 写入 MongoDB(持久化,支持历史查询)
await mongodb.tasks.update_one(
{"task_id": task_id},
{"$set": {"status": status, **kwargs}},
upsert=True
)
8.2 任务过期处理
当 Redis 中的任务状态过期后,不再返回 404,而是返回"已完成"状态:
@router.get("/tasks/{task_id}")
async def get_task_status(task_id: str):
task_data = await redis.get(f"task:{task_id}")
if not task_data:
# Redis 中已清除 = 大概率已完成
return {"status": "completed"}
return json.loads(task_data)
8.3 任务历史记录
基于 MongoDB 的任务集合,实现了完整的任务历史记录管理:CRUD 操作、列表查询、进度跟踪。前端提供任务历史页面,用户可以查看、删除历史任务记录。
相关提交:858b594, 0dbf74d, ddf3007
九、团队协作与 Git 管理
9.1 多人协作的合并冲突
项目有至少 4 位贡献者(KiriAky, dj, tl, zzz),在开发高峰期频繁出现合并冲突。
冲突高发区域:
template_fill_service.py— 核心填写逻辑llm_service.py— LLM 调用参数前端 API 接口定义
典型冲突场景:
一方优化了字段提取逻辑(增加了 RAG 加速)
另一方也修改了同一方法(增加了 Word 文档支持)
→ 合并时需要仔细对比,保留双方改进
解决经验:
功能模块物理隔离:不同开发者负责不同的 Service 文件
及时 Pull + Rebase:每天早上先拉最新代码
合并前 review:关键文件合并前通过代码审查
相关提交:df35105, 8e713be, 38b0c7e
9.2 提交规范与追溯
项目后期形成了规范的提交格式:
feat(module): 简短描述
- 详细变更点1
- 详细变更点2
fix(module): 问题描述
- 修复内容
这极大方便了后续的问题追溯和博客撰写。
十、关键经验总结
10.1 技术层面的七大教训
10.2 架构设计的经验
分层清晰:API 层 → Service 层 → Parser 层 → Database 层,职责分明
依赖注入:通过
settings对象统一管理配置,方便切换环境工厂模式:
ParserFactory根据文件扩展名自动选择解析器异步优先:所有 I/O 密集型操作(数据库、LLM 调用)使用 async/await
双轨制提取:结构化数据直接提取 + LLM 文本提取,兼顾速度与覆盖面
10.3 项目管理经验
MVP 先行:先完成 Excel 解析+统计图表(最小闭环),再逐步扩展
比赛导向:根据比赛评分规则(准确率优先于速度)调整技术方案
技术栈克制:不追新求异,选择成熟稳定的技术组合
文档先行:
开发路径.md、比赛备赛规划.md等文档帮助团队对齐目标Docker 化收尾:最后阶段的容器化部署极大简化了环境搭建
十一、技术栈全景图
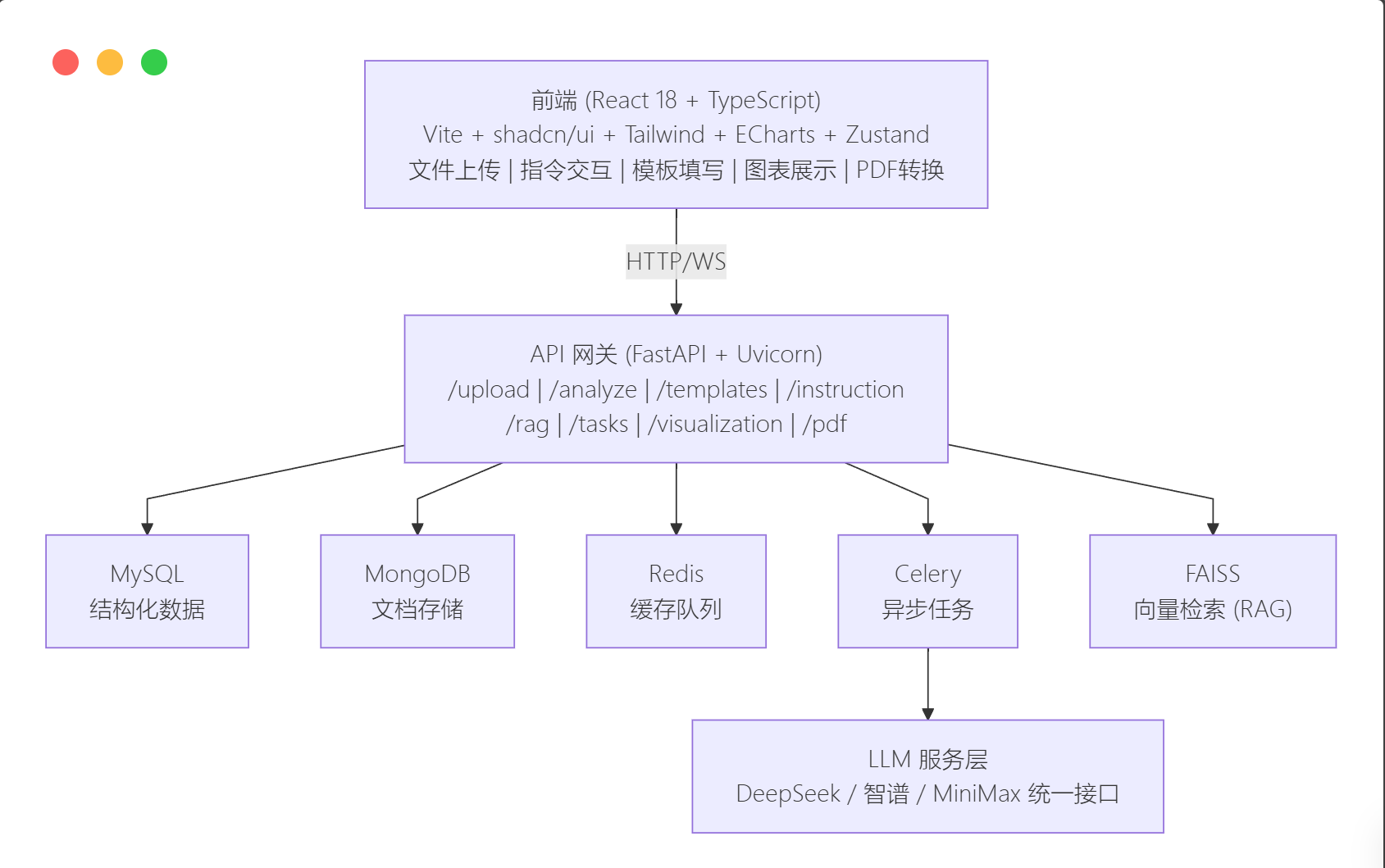
十二、项目数据一览
基于 Git 统计:
总提交数:约 60+ 个有意义提交
开发周期:2026年2月 ~ 2026年5月(约3个月)
代码变更:218 files changed, 44,332+ insertions
后端服务:15+ 个 Service 类
API 端点:20+ 个接口
前端页面:7+ 个主要页面
支持格式:4 种输入(xlsx, docx, md, txt)+ PDF 导出
数据库:3 种(MySQL, MongoDB, Redis)
LLM 供应商:3 家(MiniMax, 智谱AI, DeepSeek)
后端语言:Python 3.12(FastAPI + Celery)
前端语言:TypeScript(React 18 + Vite)
后记
"表易智融"项目从零开始,在三个月内完成了一个功能完备的多格式文档理解与智能填表系统。整个过程充满了技术挑战:LLM 输出的不确定性、Excel 格式的多样性、RAG 模型部署的复杂性、多数据库协同的细节陷阱、多人协作的合并冲突……
但也正是这些挑战,让团队在实战中积累了宝贵的经验。从最初的简单 Excel 解析到最终的自然语言驱动的智能文档平台,每一步迭代都在解决真实的问题。
最重要的感悟:在 LLM 应用开发中,不要试图让 AI 包办一切。合理的策略是——能用代码精确处理的,绝不让 AI 猜;AI 的输出,永远要有容错和兜底机制。 正是这种"结构化优先 + LLM 增强 + 容错兜底"的组合策略,让系统在准确性和鲁棒性之间找到了平衡点。
希望这篇博客能帮助到正在构建类似 LLM 应用系统的开发者——少走一些我们走过的弯路。
📎 项目仓库:FilesReadSysteam
🏆 赛题:第十七届中国大学生服务外包创新创业大赛 A23 选题
博客最后更新:2026年6月8日
基于 60+ 个 Git 提交记录、项目文档及源码分析撰写



